Type
convolutional attention
成功的语义分割具有几点关键点
- 使用强主干网络作为编码器
- 多尺度信息交互
- 空域注意力
- 低计算复杂度
本文方案
与其他工作相似性
SegNext所用到的定制化骨干网络(Encoder)其实就是扩展版的VNN
Encoder
本文 Encoder 采用了金字塔结构的多尺度卷积注意力模块(MSCA)
金字塔结构的好处
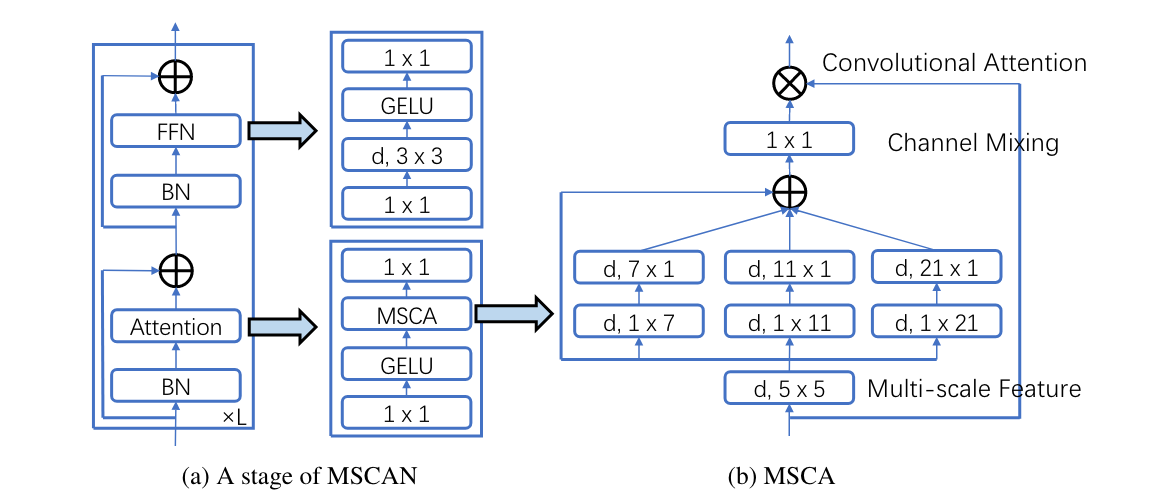
MSCA 由三部分组成:
- a depth-wise convolution to aggregate local information
- multi-branch depth-wise strip convolutions to capture multi-scale context
- 1 × 1 convolution to model relationship between different channels.
MSCA 使用了Strip卷积(To mimic a standard 2D convolution with kernel size 7 × 7, we only need a pair of 7 × 1 and 1 × 7 convolutions.)代替了标准的2D卷积。
使用Strip卷积的好处:
- more lightweight
- strip convolution can be a complement of grid convolutions(standard convolution) and helps extract strip-like features
MSCA使用了BN(Batch Nomolization)而非LN(layer normalization)进行Scale
归一化的作用:
消除不同评价指标的量纲影响
归一化的目的就是使得预处理的数据被限定在一定的范围内(比如[0,1]或者[-1,1]),从而减小***奇异样本数据***导致的不良影响。
- 在统计学中,归一化的具体作用是归纳统一样本的统计分布性。归一化在0
1之间是统计的概率分布,归一化在-1+1之间是统计的坐标分布。- 奇异样本数据是指相对于其它输入样本特别大或特别小的样本矢量(即特征向量)。
奇异样本数据的存在会引起训练时间增大,同时也可能导致无法收敛。因此,当存在奇异样本数据时,在进行训练之前需要对预处理数据进行归一化;反之,不存在奇异样本数据时,则可以不进行归一化。
Decoder
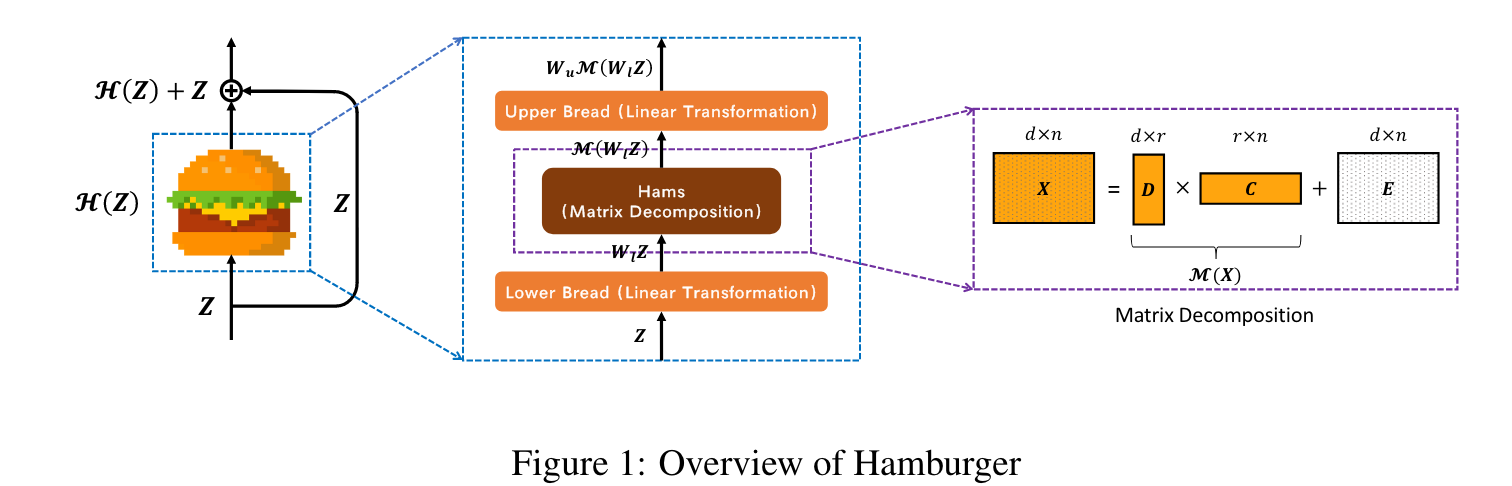
本文使用轻量型的Hamberger模块对后三个阶段的特性金鑫聚合一进行全局上下文建模
本文只对阶段2-4进行聚合,原因:
- 使用卷积架构,第一阶段部分特征包含了过多的底层信息,会影响语义分割的性能
拓展阅读:Hamberger 架构
参考文献
Geng, Z., Guo, M.-H., Chen, H., Li, X., Wei, K., & Lin, Z. (2021). Is Attention Better Than Matrix Decomposition? (arXiv:2109.04553). arXiv. https://doi.org/10.48550/arXiv.2109.04553
Guo, M.-H., Lu, C.-Z., Hou, Q., Liu, Z., Cheng, M.-M., & Hu, S.-M. (2022). SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation (arXiv:2209.08575). arXiv. http://arxiv.org/abs/2209.08575